Как системный интегратор создал приложение для датчиков с IoT Query, а не используя API

АвторAndrew M., VP of Data and Solutions
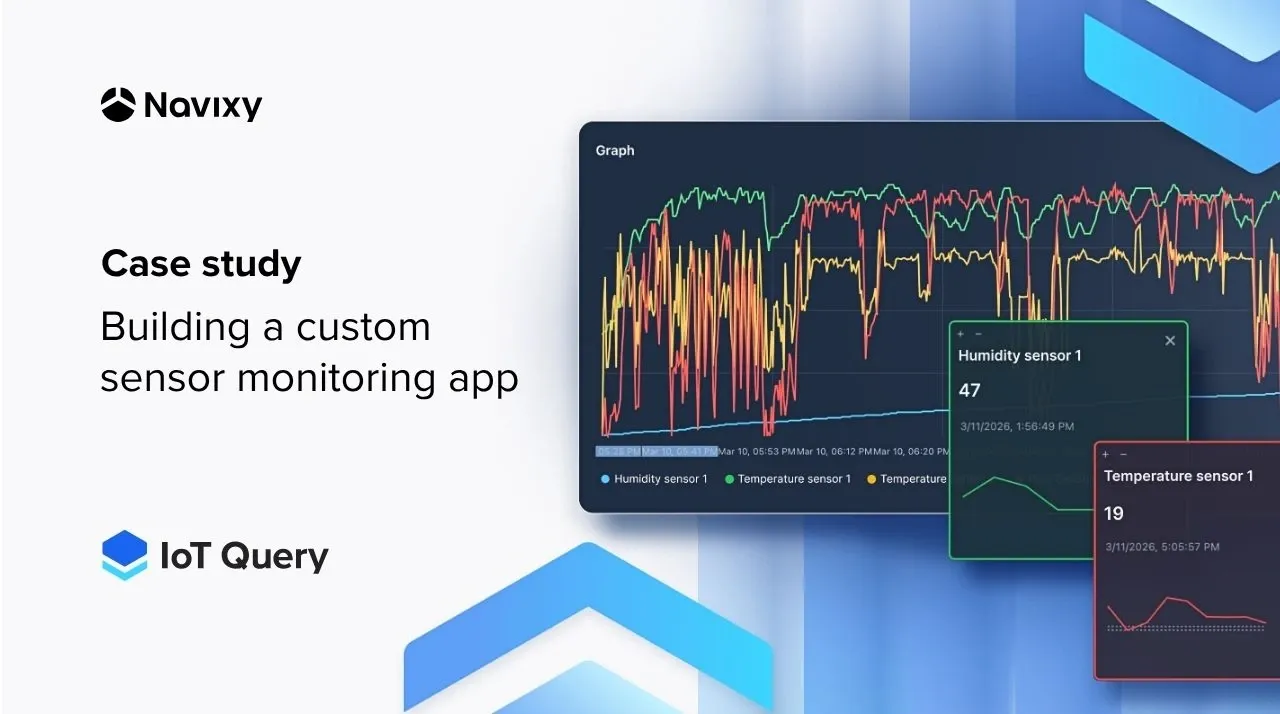
Руководитель склада пытается найти показания температуры в панели мониторинга автопарка, спрятанные в трех уровнях меню. Данные там есть, но интерфейс рассчитан на диспетчеров, а не на управление холодильными помещениями. Такой разрыв между возможностями платформы и бизнес-потребностями встречается часто. Создание пользовательских приложений обычно занимает месяцы, но этот пример демонстрирует более быстрый путь.
Основные тезисы
- Создавайте собственные приложения мониторинга быстрее за счет прямого доступа к телеметрии, устраняя потребность в промежуточном ПО и сложных конвейерах данных.
- Упростите разработку аналитики, используя SQL для прямого запроса исторических данных и избегая издержек и ограничений интеграций на базе API.
- Создавайте панели мониторинга для конкретных ролей, используя гибкие SQL-запросы, которые максимально соответствуют операционным процессам, повышая удобство и эффективность принятия решений.
- Масштабируйтесь без проблем на разные склады и пользователей, не перестраивая инфраструктуру и не управляя ограничениями API.
- Ускорьте получение результата, сосредоточившись на аналитике и выводах с помощью SQL, а не на поддержке серверных сервисов или интеграциях через API.
Изучите IoT Query, чтобы раскрыть весь потенциал ваших телематических данных для создания собственных аналитических приложений.
Оперативная реальность специализированного мониторинга
Универсальные телематические платформы хорошо справляются со своими задачами: отслеживание транспорта, оптимизация маршрутов, анализ поведения водителей. Но когда логистической компании требуется отслеживание параметров окружающей среды в нескольких складских помещениях, тот же интерфейс превращается в помеху.
В этом случае руководителям складов нужно было нечто конкретное:
- Показания температуры и влажности по 12 зонам хранения.
- Исторические тренды для расследования инцидентов.
- Выделение ситуаций, когда условия выходят за допустимые пределы.
Традиционно для решения этой задачи приходилось идти одним из двух путей: либо «растягивать» API и существующие платформы за пределы их назначений, либо создавать отдельный стек приложений со своими конвейерами данных, инфраструктурой и управлением ролями. Оба подхода добавляют лишнюю сложность. Первый вызывает громоздкие интеграции и ограничивает гибкость аналитики, второй замедляет внедрение: командам приходится тратить недели и месяцы на сборку конвейеров данных, поддержку инфраструктуры и согласование различных источников данных, вместо создания ценности.
Задача: сохранить независимость и обеспечить интеграцию
Системный интегратор столкнулся со списком требований, которые на первый взгляд выглядели простыми, но имели серьезные архитектурные последствия. Сенсоры уже были развернуты в складской сети, передавая телеметрию в Navixy. Температура, влажность, состояние дверей и данные о работе оборудования непрерывно поступали в платформу.
Но руководителям требовался интерфейс, в котором отражалось только то, что нужно их рабочему процессу:
- Отображение статуса в реальном времени.
- Исторические запросы для выяснения, почему в морозильной камере в зоне 3 во вторник произошел скачок температуры.
- Отдельные представления для клиентов, желающих иметь доступ к своим зонам хранения.
Также приложение должно было оставаться независимым и в то же время оставаться связанным с телематической платформой. При добавлении новых складов и сенсоров не должно быть необходимости перестраивать приложение. Права пользователей должны сохранять имеющуюся организационную структуру.
Масштабирование включало три аспекта: больше зон в рамках одного склада, больше складов в сети и больше пользователей с разными уровнями доступа. Архитектура должна была поддержать все эти варианты, не требуя доработок для каждого расширения.
Архитектурное решение: почему прямой доступ к данным эффективнее API
Существовали два возможных пути к работающему приложению. Первый — использование API платформы, что является традиционным вариантом. Второй — прямой доступ с помощью IoT Query, который открывает другую конфигурацию.
Подход с использованием API отлично подходит во многих интеграциях, особенно если требуется информация в реальном времени. Но когда речь заходит об исторической аналитике, ситуация меняется. Запрашивать через API данные о температуре за шесть месяцев по 12 зонам означает сталкиваться с пагинацией, ограничениями по скорости запросов и логикой агрегации, реализованной в отдельном промежуточном решении. Интегратору пришлось бы разворачивать и обслуживать локальную базу данных, механизмы синхронизации и хранилище, прежде чем приступить к написанию кода самой панели мониторинга.
IoT Query предложил другую архитектуру. Приложение напрямую запрашивает подготовленный слой данных с помощью стандартного SQL.
"IoT Query предоставляет готовый доступ к оперативным и историческим телеметрическим данным без необходимости создания собственных слоев хранения и агрегации, — объясняет Эндрю Мельник, вице-президент по направлениям Data и Solutions в Navixy. — SQL-запросы работают быстрее, чем повторяющиеся вызовы API. В результате мы можем обслуживать панели мониторинга в режиме реального времени и историческую аналитику из единого источника данных, что упрощает архитектуру. Приложение остается независимым, но при этом легко интегрируется с Navixy. Особенно для данного кейса нагрузка на сопровождение значительно ниже по сравнению с методом API».
Реализация: от доступа к базе данных к рабочим панелям мониторинга
Когда архитектурное решение было принято, реализация сосредоточилась на том, что системные интеграторы умеют делать лучше всего: на создании приложений для конкретных бизнес-задач.
IoT Query raw data layer стал основой. В этом наборе данных хранятся телеметрические показания с необходимой структурой и индексированием для анализа временных рядов: температура, влажность, состояния дверей, показатели работы оборудования — все это доступно через SQL-запросы, совместимые со стандартными инструментами PostgreSQL.
Процесс разработки выглядел привычно для тех, кто создавал аналитические приложения:
- Подключиться к источнику данных.
- Написать запросы для необходимых метрик.
- Построить визуализации, которые отвечают на актуальные вопросы бизнеса.
Для мониторинга в реальном времени приложение запрашивает последние показания и обновляет панели с периодичностью, подходящей для отслеживаемых условий (для холодных складов часто достаточно часов, а не минут). Для исторического анализа используется тот же источник данных, который поддерживает запросы за недели или месяцы без сложной пагинации, присущей API.
Изоляция данных по клиентам осуществляется через уже существующую организационную структуру. Каждый клиент склада видит только свои зоны хранения. Приложению не нужно добавлять отдельную логику разграничения доступа.
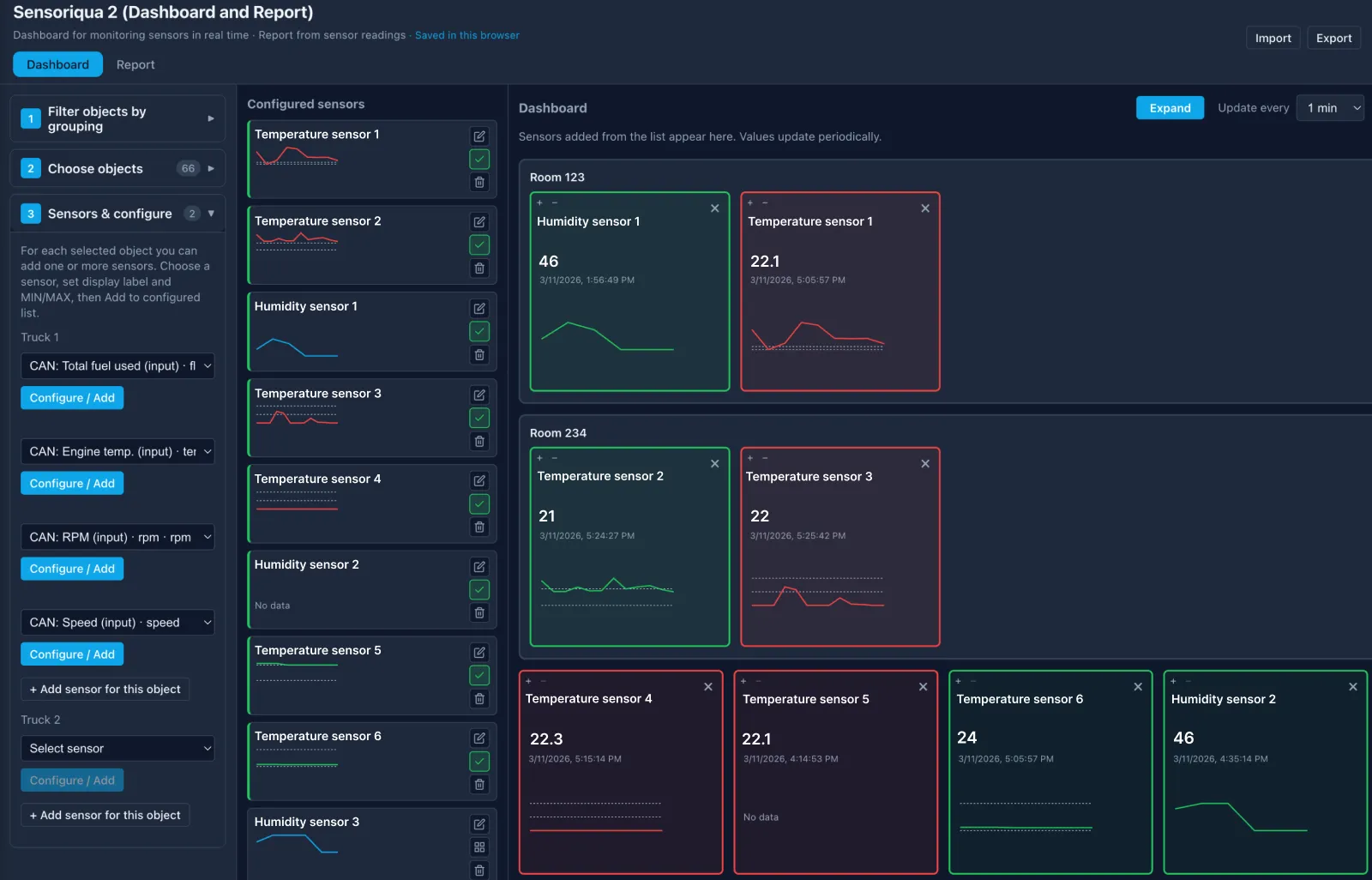
Результирующее приложение предоставляет руководителям ровно то, что необходимо:
- Экологические параметры в реальном времени по всем контролируемым зонам.
- Исторические тенденции для анализа аномалий.
- Оповещения о выходе показателей за допустимые границы.
- Представления для каждого клиента с изоляцией данных.
Приложение работает как независимый инструмент, но открывается внутри интерфейса Navixy, создавая единую среду для пользователей, работающих как с автопарком, так и со складскими операциями.
Эта интеграция достигается при помощи App Connect, инструмента аутентификации от Navixy. Он передает аутентификацию пользователей с платформы во внешнее приложение, исключая необходимость отдельной авторизации. Для системных интеграторов это означает, что им не нужно разрабатывать и поддерживать собственную систему аутентификации.
Что дальше: от мониторинга к прогнозированию
По мере масштабирования приложения на панель можно добавить новые ключевые показатели (KPI), выходящие за рамки температуры и влажности. Показатели времени работы оборудования, энергопотребления и технического обслуживания могут быть легко добавлены с использованием того же слоя данных.
Следующим этапом может стать предиктивная аналитика. Вместо того чтобы только уведомлять, когда показатели выходят за пределы, система сможет выявлять закономерности, предшествующие сбоям. Например, компрессор, который слишком часто включается. Датчик двери, показывающий необычно долгую открытость. Все эти сигналы уже содержатся в исторических данных и ждут анализа.
Механизмы оповещения выйдут за пределы самого приложения. Интеграция с рабочими процессами позволит заинтересованным сотрудникам оперативно получать уведомления по привычным каналам (электронная почта, мессенджеры), а при необходимости — отключать или ограничивать их.
Мобильные интерфейсы расширят возможности руководителей на местах. Те же запросы, что формируют десктопные панели, могут строить и компактные мобильные представления для отображения статуса зон и недавних уведомлений во время обхода склада.
Важна фундаментальная основа: все эти расширения требуют минимальных изменений в архитектуре. Слой данных уже содержит необходимые сигналы для более сложного анализа. Добавление новых представлений и аналитики становится задачей разработки приложения, а не инфраструктуры.
Аргументы в пользу подхода, ориентированного на данные
Этот пример демонстрирует универсальный принцип: когда за инфраструктуру данных уже отвечают готовые инструменты, системные интеграторы могут сосредоточиться на создании приложений, реально решающих бизнес-задачи. Готовый слой данных дает разработчикам возможность работать со структурированной телеметрией на основе стандартного SQL — без управления низкоуровневыми системами.
Для системных интеграторов это весомое архитектурное преимущество. Благодаря встроенной поддержке анализа временных рядов и многопользовательской среде подготовленный слой данных может сократить сроки внедрения с нескольких месяцев до нескольких недель.
Свяжитесь с нами, чтобы подключить IoT Query и раскрыть весь потенциал ваших телематических данных для создания собственных аналитических приложений.
Часто задаваемые вопросы
Вопрос: Какие конкретные компоненты промежуточного ПО потребовались бы в случае использования только API?
Ответ: Подход на базе API требует обработки пагинации, управления лимитами запросов, локального хранилища данных, механизмов синхронизации и логики агрегации, прежде чем начать разработку панели мониторинга.
Вопрос: Как ограничения по скорости запросов и пагинации при использовании API влияют на анализ исторических данных в больших объемах?
Ответ: При проведении исторических запросов, охватывающих месяцы данных по нескольким зонам, возникает необходимость в сложной обработке пагинации. Кроме того, лимиты запросов усложняют использование данных в режиме реального времени и делают задачу анализа больших исторических объемов практически невыполнимой.
Вопрос: Как IoT Query обрабатывает несогласованные или «шумные» данные с разных устройств?
Ответ: IoT Query на данный момент предоставляет доступ к сырым данным (Raw data layer), где содержится полная телематическая и бизнес-информация с минимальной трансформацией. Согласно документации Navixy, планируется также слой Transformation для очищенных и преобразованных данных и слой Insight для агрегированных показателей, готовых к бизнес-анализу. Пока эти слои недоступны в общем доступе, поэтому интеграторам следует самостоятельно учитывать нормализацию и очистку данных в аналитических алгоритмах.
Вопрос: Что происходит, если данные от датчиков задерживаются или отсутствуют?
Ответ: Доступность данных зависит от подключения устройства и способа его передачи. IoT Query отражает данные, которые поступают на платформу. Интеграторам рекомендуется учитывать пропуски, задержки и неполные наборы данных в логике собственных панелей и алгоритмов.
Вопрос: Какие ограничения или важные аспекты нужно учитывать при использовании IoT Query в крупномасштабных проектах?
Ответ: Производительность зависит от конструкции запросов, объема данных и диапазона времени. Хотя IoT Query избавляет от необходимости в собственной инфраструктуре хранения, интеграторам стоит продумать эффективность запросов, время отклика при больших массивах данных и частоту обновления панелей в реальных условиях нагрузки.
Вопрос: Как IoT Query интегрируется со сторонними системами или инструментами бизнес-аналитики (BI)?
Ответ: IoT Query поддерживает SQL-доступ, совместимый с PostgreSQL, что позволяет внешним аналитическим инструментам и пользовательским приложениям подключаться к данным как к обычной реляционной базе.
Вопрос: Как организуется контроль доступа и изоляция данных разных клиентов?
Ответ: IoT Query следует организационной структуре платформы, гарантируя, что пользователи могут запрашивать и видеть только данные своему аккаунту и разрешениям.
На этой странице
- Оперативная реальность специализированного мониторинга
- Задача: сохранить независимость и обеспечить интеграцию
- Архитектурное решение: почему прямой доступ к данным эффективнее API
- Реализация: от доступа к базе данных к рабочим панелям мониторинга
- Что дальше: от мониторинга к прогнозированию
- Аргументы в пользу подхода, ориентированного на данные
- Часто задаваемые вопросы