Comment un intégrateur de systèmes a construit une application de capteurs avec IoT Query, sans APIs

AuteurAndrew M., VP of Data and Solutions
Un superviseur d’entrepôt recherche des relevés de température sur un tableau de bord de gestion de flotte, enfouis à trois niveaux de menus. Les données sont bien présentes, mais l’interface est conçue pour les répartiteurs, pas pour les opérations de stockage à froid. Ce décalage entre les capacités de la plateforme et les besoins métier est fréquent. La création d’applications personnalisées prend généralement des mois, mais cette étude de cas propose une voie plus rapide.
Key takeaways
- Créer des applications de surveillance personnalisées plus rapidement grâce à un accès direct à la télémétrie, sans avoir besoin de middleware ni de pipelines de données complexes.
- Simplifier le développement analytique en utilisant SQL pour interroger directement les données historiques, évitant ainsi la charge et les limitations des intégrations basées sur des APIs.
- Créer des tableaux de bord spécifiques à chaque rôle avec des requêtes SQL flexibles qui correspondent étroitement aux flux de travail opérationnels, améliorant l’ergonomie et la prise de décision.
- Assurer une montée en charge fluide à travers les entrepôts et les utilisateurs, sans avoir à reconstruire l’infrastructure ni à gérer les contraintes d’API.
- Accélérer la rentabilisation en se concentrant sur l’analyse et les insights via SQL, plutôt que sur la maintenance des services backend ou des intégrations d’API.
Découvrez IoT Query pour libérer tout le potentiel de vos données télématiques et créer des applications d’analyse personnalisées.
La réalité opérationnelle d’une surveillance spécialisée
Les plateformes de télématique généralistes excellent dans ce pour quoi elles ont été conçues : le suivi de véhicules, l’optimisation d’itinéraires, l’analyse du comportement du conducteur. Mais lorsqu’une entreprise de logistique a besoin de surveiller l’environnement dans plusieurs salles d’entrepôt, la même interface devient un obstacle.
Dans ce cas, les superviseurs avaient besoin de quelque chose de précis :
- Des relevés de température et d’humidité à travers 12 zones de stockage.
- Des tendances historiques pour la recherche d’incidents.
- Une mise en évidence lorsque les conditions sortent des plages acceptables.
Traditionnellement, pour résoudre ce problème, deux approches étaient possibles : soit étendre les APIs et les plateformes existantes au-delà de leur finalité initiale, soit construire une pile applicative distincte avec des pipelines de données, une infrastructure et une gestion des rôles sur mesure. Les deux voies ajoutent une complexité inutile. La première aboutit à des intégrations et offre une flexibilité analytique limitée. La seconde ralentit la mise en œuvre, car les équipes passent des semaines et des mois à assembler des pipelines de données, à maintenir l’infrastructure et à unifier plusieurs sources de données au lieu de générer de la valeur.
Le défi : concilier indépendance et intégration
L’intégrateur de systèmes était confronté à une liste d’exigences qui paraissait simple mais comportait des implications architecturales. Des capteurs étaient déjà déployés dans l’ensemble du réseau d’entrepôts, envoyant leur télémétrie à Navixy. Température, humidité, états des portes et données de fonctionnement des équipements circulaient en continu.
Mais les superviseurs avaient besoin d’une interface qui n’affiche que ce qui compte pour leur flux de travail :
- Un état en temps réel, d’un seul coup d’œil.
- Des requêtes historiques pour comprendre pourquoi le congélateur de la zone 3 a affiché un pic de température mardi dernier.
- Des vues spécifiques aux clients qui souhaitent une visibilité sur leurs zones de stockage dédiées.
L’application devait aussi rester indépendante, un outil ciblé pour les opérations d’entrepôt, tout en restant connecté à la plateforme télématique. Les nouveaux entrepôts et capteurs devaient s’intégrer sans qu’il faille reconstruire l’application. Les autorisations utilisateurs devaient respecter la structure organisationnelle existante.
La montée en charge signifiait trois choses : plus de salles au sein d’un entrepôt, plus d’entrepôts dans le réseau, et plus d’utilisateurs avec différents niveaux de permission. L’architecture devait supporter ces trois dimensions sans exiger de développements spécifiques à chaque extension.
Décision architecturale : pourquoi l’accès direct aux données l’emporte sur l’approche par API
Deux stratégies architecturales pouvaient aboutir à une application fonctionnelle. La première, l’utilisation des APIs de la plateforme, est le choix conventionnel. La seconde, l’accès direct via IoT Query, offrait un compromis différent.
L’option basée sur les APIs fonctionne bien pour de nombreuses intégrations, notamment les tableaux de bord en temps réel. Mais l’analyse historique change la donne. Interroger six mois de données de température sur 12 zones via une API implique la pagination, des limites de débit et une logique d’agrégation gérée par un middleware personnalisé. L’intégrateur doit alors créer et maintenir une base de données locale, des routines de synchronisation et une infrastructure de stockage, avant même d’écrire la moindre ligne de code pour le tableau de bord.
IoT Query proposait une autre architecture. L’application interroge directement une couche de données prête à l’emploi à l’aide de SQL standard.
"IoT Query offre un accès prêt à l’emploi aux données télématiques en temps réel et historiques, sans qu’il soit nécessaire de créer des couches de stockage et d’agrégation", explique Andrew Melnik, Navixy VP of Data and Solutions. "Les requêtes SQL s’exécutent plus rapidement que les appels API répétés. Nous pouvons donc fournir des tableaux de bord en temps réel et des analyses historiques à partir de la même source de données, ce qui simplifie la conception. L’application reste indépendante mais s’intègre parfaitement à Navixy. Pour ce cas d’usage, la charge de maintenance est considérablement plus faible que dans l’approche par API."
Mise en œuvre : de l’accès à la base de données aux tableaux de bord opérationnels
La couche de données brutes d’IoT Query a servi de fondation. Cet ensemble de données contient les relevés de télémétrie avec la structure et l’indexation requises pour l’analyse de séries temporelles. Relevés de température, mesures d’humidité, états des portes et statut des équipements, tous accessibles via la syntaxe SQL standard compatible avec PostgreSQL.
Le schéma de développement est familier à quiconque a déjà construit des applications analytiques :
- Se connecter à la source de données.
- Rédiger des requêtes pour les indicateurs spécifiques requis.
- Créer des visualisations qui répondent aux questions opérationnelles.
Pour la surveillance en temps réel, l’application interroge les relevés récents et met à jour les tableaux de bord à un intervalle correspondant aux conditions environnementales (les changements à la minute sont moins cruciaux que les tendances à l’heure pour le stockage à froid). Pour l’analyse historique, la même source de données permet des requêtes sur plusieurs semaines ou mois sans la complexité de la pagination liée aux APIs.
L’isolement des données clients est garanti par la structure organisationnelle existante. Chaque client d’entrepôt ne voit que ses zones de stockage assignées. L’application respecte ces limites sans nécessiter de logique de contrôle d’accès personnalisée.
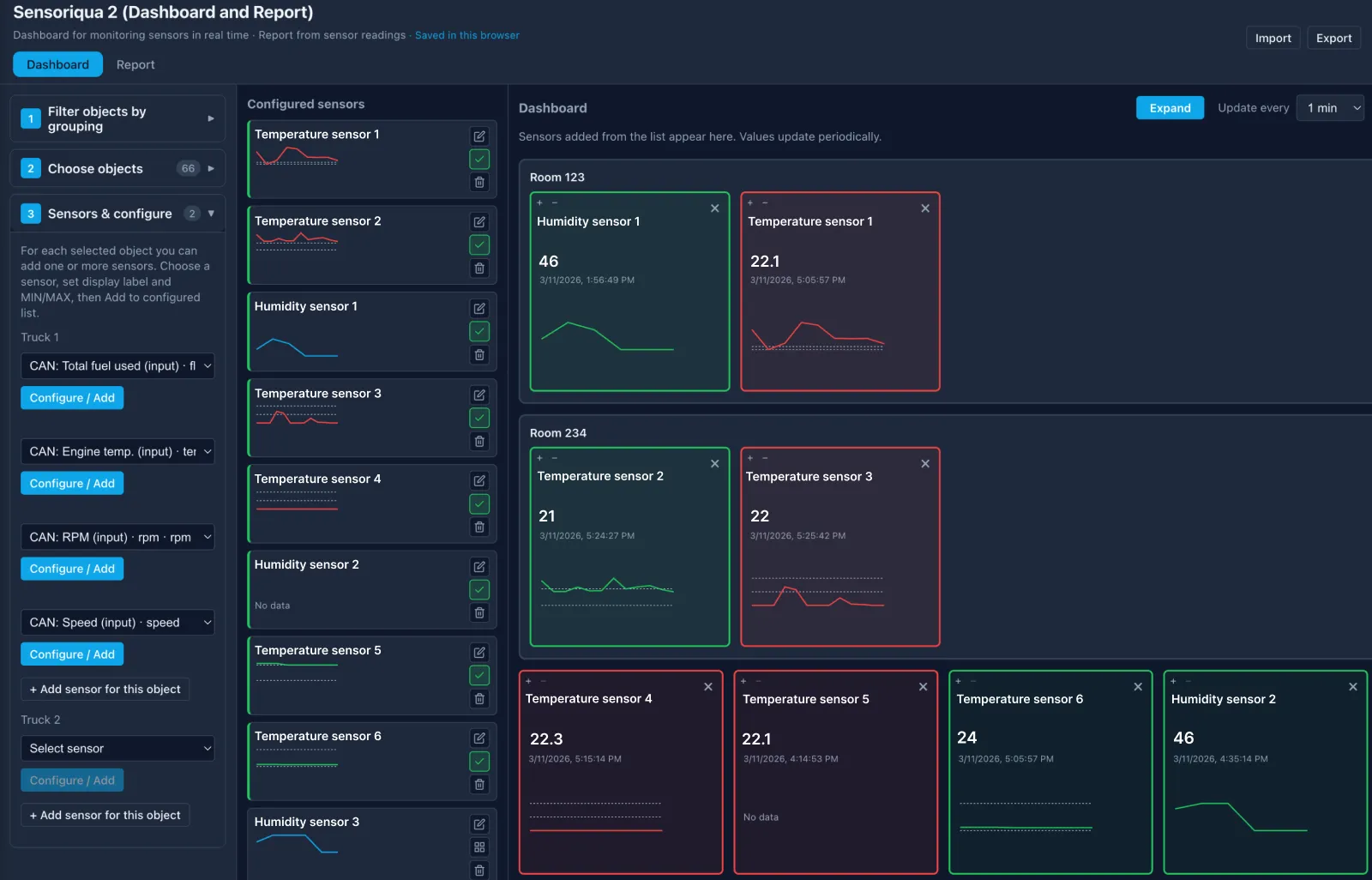
L’application livrée fournit aux superviseurs exactement ce dont ils ont besoin :
- Un statut environnemental en temps réel pour toutes les zones surveillées.
- Des graphiques de tendances historiques pour analyser les anomalies.
- Des alertes basées sur des seuils lorsque les conditions dépassent les limites acceptables.
- Des vues spécifiques pour chaque client, avec une isolation appropriée des données.
L’application fonctionne comme un outil indépendant, mais s’ouvre depuis l’interface Navixy, assurant une expérience cohérente pour les utilisateurs qui travaillent à la fois sur le parc de véhicules et la gestion d’entrepôt.
Cette intégration est rendue possible grâce à App Connect, l’outil d’authentification de Navixy. Il transfère l’authentification de l’utilisateur depuis la plateforme vers l’application externe, permettant ainsi aux utilisateurs d’accéder à l’outil de surveillance sans identifiants supplémentaires. Pour les intégrateurs de systèmes, cela évite la nécessité de créer ou de maintenir une infrastructure d’authentification.
Et ensuite : de la surveillance à la prédiction
Au fur et à mesure que l’application s’étend, d’autres indicateurs de performance (KPIs) pourront compléter le tableau de bord au-delà de la température et de l’humidité. Des métriques telles que le temps de fonctionnement des équipements, la consommation d’énergie et les indicateurs de maintenance peuvent être intégrés sans difficulté en utilisant la même couche de données.
L’analyse prédictive représente la prochaine étape d’amélioration opérationnelle. Au lieu d’alerter lorsque les conditions dépassent les seuils, le système peut identifier les schémas qui précèdent les défaillances. Un compresseur qui se déclenche plus souvent que la normale. Un capteur de porte qui signale des ouvertures inhabituelles. Ces signaux existent dans les données historiques et n’attendent qu’à être analysés.
Les mécanismes d’alerte iront au-delà de l’application elle-même. L’intégration avec les flux de travail opérationnels garantit que les bonnes personnes reçoivent les notifications via leurs canaux existants (e-mail, messageries), tout en permettant de réduire ou de désactiver certaines alertes si nécessaire.
Les interfaces mobiles étendront l’accès aux superviseurs lors de leurs rondes dans l’installation. Les mêmes requêtes qui alimentent les tableaux de bord sur ordinateur peuvent rendre possible des vues mobiles ciblées indiquant l’état des zones et les alertes récentes.
Le socle est essentiel, car ces extensions nécessitent peu de modifications architecturales. La couche de données contient déjà les signaux nécessaires à une analyse plus avancée. Créer de nouvelles vues et analyses relève du développement applicatif, non du travail d’infrastructure.
La puissance d’une approche orientée données
Cette étude de cas illustre un principe qui dépasse la simple surveillance d’entrepôt : lorsque l’infrastructure de données est gérée, les intégrateurs de systèmes peuvent se concentrer sur des applications qui résolvent de vrais problèmes. Une couche de données prête à l’emploi permet aux développeurs d’interroger une télémétrie structurée via SQL standard — sans avoir à gérer les systèmes sous-jacents.
Pour les intégrateurs de systèmes, c’est un atout architectural. Grâce à la prise en charge native de l’analyse de séries temporelles et des environnements multi-locataires, une couche de données prête à l’emploi peut réduire la livraison de plusieurs mois à quelques semaines.
Contactez-nous pour activer IoT Query et libérer tout le potentiel de vos données télématiques pour des applications d’analyse personnalisées.
Frequently Asked Questions
Q : Quels composants middleware spécifiques une approche uniquement basée sur l’API nécessiterait-elle ?
R : Une approche via API exige de gérer la pagination, les limites de débit, le stockage dans une base de données locale, les routines de synchronisation et la logique d’agrégation avant même de commencer le développement du tableau de bord.
Q : Comment les limites de débit et la pagination des APIs affectent-elles l’analyse de données historiques à grande échelle ?
R : Les requêtes historiques qui couvrent plusieurs mois de données sur plusieurs zones impliquent une gestion de la pagination complexe et sont limitées par les contraintes de débit de l’API, rendant l’analyse historique en temps réel impraticable.
Q : Comment IoT Query gère-t-il des données de capteurs incohérentes ou bruitées provenant de divers appareils ?
R : IoT Query fournit actuellement un accès à une couche de données Raw, qui contient l’ensemble des données télématiques et métiers avec un minimum de transformation. Selon la documentation Navixy, les couches Transformation, pour un nettoyage et une transformation des données, ainsi que la couche Insight, pour des agrégats prêts à l’emploi, sont prévues mais pas encore disponibles. Les intégrateurs travaillent donc principalement sur les données brutes et doivent prendre en compte la normalisation et le nettoyage dans leur propre logique analytique si nécessaire.
Q : Que se passe-t-il lorsque les données de télémétrie sont retardées ou manquantes ?
R : La disponibilité des données dépend de la connectivité et du comportement de transmission des appareils. IoT Query reflète les données reçues par la plateforme, de sorte que les intégrateurs doivent concevoir des tableaux de bord et une logique capables de gérer les lacunes, retards et ensembles de données incomplets.
Q : Quelles sont les limites pratiques ou considérations à prendre en compte lors de l’utilisation d’IoT Query pour des déploiements à grande échelle ?
R : Les performances dépendent du design des requêtes, du volume de données et de la plage temporelle. Bien qu’IoT Query supprime le besoin d’infrastructure de stockage personnalisée, les intégrateurs doivent veiller à l’efficacité des requêtes, aux temps de réponse pour de grands volumes de données, et à la fréquence de rafraîchissement des tableaux de bord en conditions réelles.
Q : Comment IoT Query s’intègre-t-il à des systèmes ou outils BI externes ?
R : IoT Query prend en charge un accès basé sur SQL compatible avec PostgreSQL, ce qui permet l’intégration avec des outils analytiques externes et des applications personnalisées pouvant se connecter à des bases de données relationnelles.
Q : Comment sont gérés le contrôle d’accès et l’isolation multi-locataires des données ?
R : IoT Query s’aligne sur la structure organisationnelle de la plateforme, garantissant que les utilisateurs ne peuvent accéder et interroger que les données disponibles dans leur compte et leurs autorisations attribuées.
Sur cette page
- La réalité opérationnelle d’une surveillance spécialisée
- Le défi : concilier indépendance et intégration
- Décision architecturale : pourquoi l’accès direct aux données l’emporte sur l’approche par API
- Mise en œuvre : de l’accès à la base de données aux tableaux de bord opérationnels
- Et ensuite : de la surveillance à la prédiction
- La puissance d’une approche orientée données
- Frequently Asked Questions